
Arbeitsbereich Technische Informatik
|
Wilhelm-Schickhard-Institut für Informatik Arbeitsbereich Technische Informatik |
![[*]](footnote.png) sind kleine, dafür aber sehr schnelle Speicher, die in nahezu allen
modernen Computersystemen eingesetzt werden, um Zugriffe auf nachfolgende
Speichereinheiten (Hauptspeicher, Festplatten, ...) zu beschleunigen. Eine
integrierte, von den Cache-Designparametern bestimmte Logik regelt dabei,
welche Speicherabschnitte der nachfolgenden Einheit aktuell in den Cache
geladen bzw. dort gehalten werden, um eine möglichst niedrige Gesamtzugriffszeit
zu erreichen. Cache-Simulatoren werden einerseits dazu benutzt, um die
prinzipielle Performance unterschiedlicher Cache-Konfigurationen und Designparameter
zu testen. Mit Simulatoren, die die internen Vorgänge eines Caches
visualisieren, kann andererseits das Verständnis für die Bedeutung
und Funktion der einzelnen Designparameter vertieft werden. Cache-Simulatoren
sollten dabei flexibel in ihrer Konfiguration sein, um ein möglichst
breites Spektrum der unterschiedlichen Designs abzudecken. Ziel dieser
Arbeit ist daher die Entwicklung von Softwarekomponenten aus denen trace-gesteuerte,
visuelle Simulatoren für eine breite Palette von Cache-Architekturen
möglichst einfach und mit Hilfe visueller Entwicklungswerkzeuge aufgebaut
werden können. Die einzelnen Komponenten sollen dabei wiederverwendbar
und möglichst einfach zu konfigurieren sein. Um diese Ziele und gleichzeitig
eine größtmögliche Plattformunabhängigkeit mit vertretbarem
Aufwand zu erreichen, kommt für die Implementierung Java zum Einsatz.
Die Softwarekomponenten werden gemäß der JavaBeans Spezifikation
entwickelt und können so mit allen visuellen Java-Entwicklungsumgebungen,
die JavaBeans unterstützen, einfach und persistent konfiguriert werden.
Auch der Aufbau von komplexen Cache-Konfigurationen gestaltet sich mit
Hilfe dieser Werkzeuge einfach und übersichtlich. Daneben ist es natürlich
auch möglich, diese Komponenten (Beans) "klassisch", also
als Klassenbibliothek zu verwenden. Alle Komponenten werden jeweils in
einer visuellen und in einer nichtvisuellen Form getrennt entwickelt und
bereitgestellt. Die visuellen Komponenten eignen sich dabei vor allem für
den Aufbau von Simulatoren relativ kleiner Cache-Konfigurationen. Sie gestatten
eine einzelschrittweise Simulation und stellen dabei den jeweils aktuellen
Cache-Zustand detailliert grafisch dar, was vor allem für didaktische
Zwecke nützlich ist. Interessiert bei der Simulation weniger der interne
Ablauf und mehr das statistische Ergebnis der gewählten Konfiguration,
können die Simulatoren mit den nichtvisuellen Komponenten implementiert
werden, die am Ende des Simulationslaufs eine entsprechende Statistik bereitstellen.
Ein Einsatz der Komponenten in größeren Projekten, bei denen
nicht der Cache an sich Untersuchungsgegenstand ist, wird durch eine komplette
Modellierung des Datenpfads ebenfalls problemlos ermöglicht. Als Entwicklungsumgebung
und Testplattform kommt das Java 2 SDK sowie die BeanBox aus dem BDK 1.1
der Firma Sun Microsystems, Inc. zum Einsatz, welche für eine Vielzahl von Hardwareplattformen kostenlos
verfügbar sind. Kapitel cpCaches dieser Ausarbeitung stellt die für die Simulatorentwicklung
wichtigsten Grundlagen von Caches vor, gibt einen Überblick über
Designparameter und begründet die Auswahl einer trace-gesteuerten
Simulation. Die entwickelten Softwarekomponenten werden in Kapitel cpImplementierung
detailiert vorgestellt. Kapitel cpErgebnisse stellt die konkrete Anwendung
der Simulatorkomponenten in grafischen Entwicklungsumgebungen und als Klassenbibliothek
vor. Eine Zusammenfassung der Ergebnisse dieser Arbeit und ein Ausblick
schließen sich in Kapitel cpZusammenfassung an.
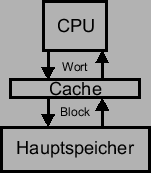
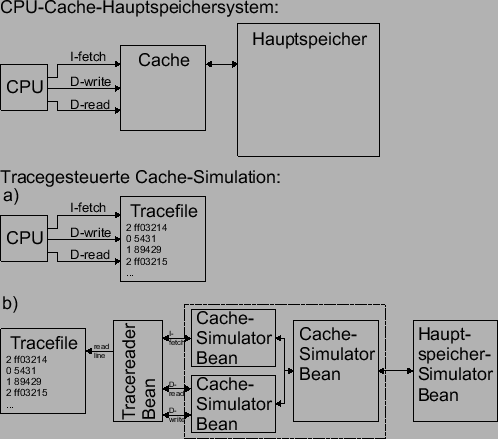
. Dieses Schema zeigt Abbildung fig:bild1.
sind kleine, dafür aber sehr schnelle Speicher, die in nahezu allen
modernen Computersystemen eingesetzt werden, um Zugriffe auf nachfolgende
Speichereinheiten (Hauptspeicher, Festplatten, ...) zu beschleunigen. Eine
integrierte, von den Cache-Designparametern bestimmte Logik regelt dabei,
welche Speicherabschnitte der nachfolgenden Einheit aktuell in den Cache
geladen bzw. dort gehalten werden, um eine möglichst niedrige Gesamtzugriffszeit
zu erreichen. Cache-Simulatoren werden einerseits dazu benutzt, um die
prinzipielle Performance unterschiedlicher Cache-Konfigurationen und Designparameter
zu testen. Mit Simulatoren, die die internen Vorgänge eines Caches
visualisieren, kann andererseits das Verständnis für die Bedeutung
und Funktion der einzelnen Designparameter vertieft werden. Cache-Simulatoren
sollten dabei flexibel in ihrer Konfiguration sein, um ein möglichst
breites Spektrum der unterschiedlichen Designs abzudecken. Ziel dieser
Arbeit ist daher die Entwicklung von Softwarekomponenten aus denen trace-gesteuerte,
visuelle Simulatoren für eine breite Palette von Cache-Architekturen
möglichst einfach und mit Hilfe visueller Entwicklungswerkzeuge aufgebaut
werden können. Die einzelnen Komponenten sollen dabei wiederverwendbar
und möglichst einfach zu konfigurieren sein. Um diese Ziele und gleichzeitig
eine größtmögliche Plattformunabhängigkeit mit vertretbarem
Aufwand zu erreichen, kommt für die Implementierung Java zum Einsatz.
Die Softwarekomponenten werden gemäß der JavaBeans Spezifikation
entwickelt und können so mit allen visuellen Java-Entwicklungsumgebungen,
die JavaBeans unterstützen, einfach und persistent konfiguriert werden.
Auch der Aufbau von komplexen Cache-Konfigurationen gestaltet sich mit
Hilfe dieser Werkzeuge einfach und übersichtlich. Daneben ist es natürlich
auch möglich, diese Komponenten (Beans) "klassisch", also
als Klassenbibliothek zu verwenden. Alle Komponenten werden jeweils in
einer visuellen und in einer nichtvisuellen Form getrennt entwickelt und
bereitgestellt. Die visuellen Komponenten eignen sich dabei vor allem für
den Aufbau von Simulatoren relativ kleiner Cache-Konfigurationen. Sie gestatten
eine einzelschrittweise Simulation und stellen dabei den jeweils aktuellen
Cache-Zustand detailliert grafisch dar, was vor allem für didaktische
Zwecke nützlich ist. Interessiert bei der Simulation weniger der interne
Ablauf und mehr das statistische Ergebnis der gewählten Konfiguration,
können die Simulatoren mit den nichtvisuellen Komponenten implementiert
werden, die am Ende des Simulationslaufs eine entsprechende Statistik bereitstellen.
Ein Einsatz der Komponenten in größeren Projekten, bei denen
nicht der Cache an sich Untersuchungsgegenstand ist, wird durch eine komplette
Modellierung des Datenpfads ebenfalls problemlos ermöglicht. Als Entwicklungsumgebung
und Testplattform kommt das Java 2 SDK sowie die BeanBox aus dem BDK 1.1
der Firma Sun Microsystems, Inc. zum Einsatz, welche für eine Vielzahl von Hardwareplattformen kostenlos
verfügbar sind. Kapitel cpCaches dieser Ausarbeitung stellt die für die Simulatorentwicklung
wichtigsten Grundlagen von Caches vor, gibt einen Überblick über
Designparameter und begründet die Auswahl einer trace-gesteuerten
Simulation. Die entwickelten Softwarekomponenten werden in Kapitel cpImplementierung
detailiert vorgestellt. Kapitel cpErgebnisse stellt die konkrete Anwendung
der Simulatorkomponenten in grafischen Entwicklungsumgebungen und als Klassenbibliothek
vor. Eine Zusammenfassung der Ergebnisse dieser Arbeit und ein Ausblick
schließen sich in Kapitel cpZusammenfassung an.
. Dieses Schema zeigt Abbildung fig:bild1.
 |
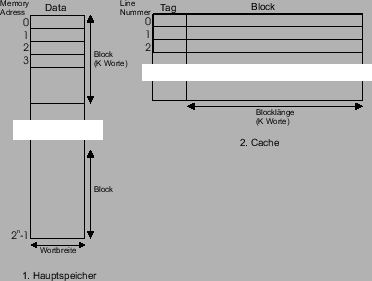 |
.
. Da bei größeren Caches auch die Zahl der zur Adressierung
benötigten gates zunimmt, neigen diese dazu, mit wachsender Größe
geringfügig langsamer zu werden. Ein weiterer Grund, die Cache-Größe
zu minimieren.
 |
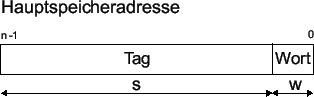 |
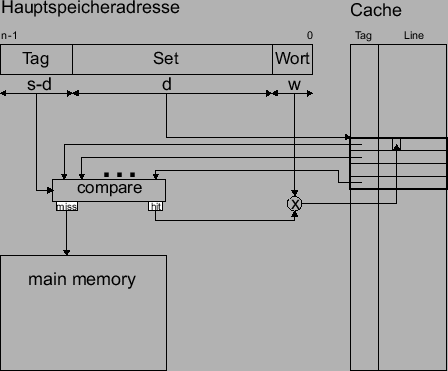 |
.
. Die entsprechenden Lösungen sind aber meist noch sehr aufwendig.
Ein System, das Cache-Inkonsistenzen verhindert, wird auch cache-koherent genannt. Das Problem der Cache-Kohärenz ist ein aktives Forschungsgebiet
und es gibt vielleicht zukünftig effektivere Wege, es zu lösen
(z.B. in [Muk98] oder [Con00]). Allocate-On-Write Eine weitere Designentscheidung bei Schreibvorgängen
betrifft das Ladeverhalten. Soll der Hauptspeicherblock, auf den sich der
Schreibvorgang bezieht, in den Cache geladen werden, oder nicht? Die erste
Variante nennt man Allocate On Write, die zweite entsprechend No Allocate On Write. Bezüglich der miss-ratio hat im allgemeinen keine der Varianten
wesentliche Vorzüge. Üblicherweise kombiniert man einen write-through
Cache mit einer No-Allocate-On-Write (siehe Abbildung fig:WT_NA) und einen
write-back Cache mit einer Allocate-On-Write Strategie (siehe Abbildung
fig:WB_AW).
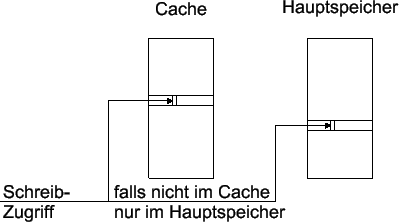 |
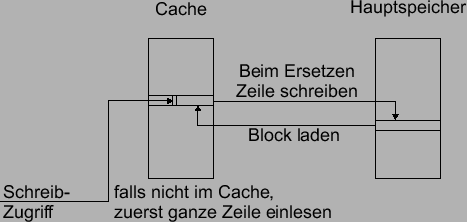 |
. Die Komplexität der Abhängigkeit der Beziehung zwischen Zeilengröße
und miss-ratio von den Lokalitätseigenschaften des jeweiligen Programms,
macht es unmöglich, eine optimale Größe zu finden. Diverse
Studien zeigen aber, dass eine Zeilengröße zwischen 4 und 8
Worten heute nahe bei einem Optimum liegt [Stall96].
 |
 |
es sich handelt. Mit solchen Traces steuert man dann ein Simulationsmodell
der gewünschten Speicherstruktur (Cache, Hauptspeicher, ...). In diesem
Simulationsmodell kann man dann sehr einfach beliebige Designparameter
testen. Trace-gesteuerte Simulation wird oft einer direkten Messung vorgezogen, da diese den Zugang zur konkreten Maschine erfordert, sehr
viel aufwendiger und kostspieliger ist, und es auch kaum ermöglicht,
Hardware-Designparameter zu variiren, was bei einer Simulation dagegen
problemlos möglich ist. Trace-gesteuerte Simulationen sind außerdem
beliebig reproduzierbar. Sie erfordern keinen Zugang zur untersuchten Hardware,
ja noch nicht einmal deren Existenz. Messungen werden dagegen oft zur Verifikation
der Ergebnisse benutzt, da sie wiederum einen realitätsnahen workload
(incl. supervisor code, interrupts, context switches, etc.) repräsentieren,
der mit Traces sehr schwer zu modellieren ist. Die in dieser Arbeit entwickelten Simulations-Komponenten verwenden
ebenfalls Traces zur Simulationssteuerung.
einzubinden. Der Simulator kann sich also nicht nur darauf beschränken,
die für die Statistik und Visualisierung relevanten Aspekte abzubilden.
Er muß sich wie ein "realer" Cache verhalten und im Gegensatz
zu den meisten anderen Cache-Simulatoren, wirklich Daten speichern. Für die Implementierung wurde aus diesen Gründen Java gewählt
und die Softwarekomponenten werden gemäß der JavaBeans-Spezifikation
entwickelt, was eine Verwendung mit allen visuellen Java-Entwicklungsumgebungen,
die JavaBeans unterstützen, ermöglicht. Der Aufbau von komplexen
Cache-Konfigurationen gestaltet sich mit Hilfe dieser Werkzeuge einfach
und übersichtlich. Eine "klassische" Verwendung der Komponenten
ist natürlich ebenfalls möglich. Dazu wird eine entsprechende
Klassenbibliothek bereitgestellt. Um Perfomanceeinschränkungen, die
bei Java Programmen im allgemeinen zur Zeit noch vorhanden sind, etwas
abzumildern, werden alle Komponenten jeweils in einer visuellen und in
einer nichtvisuellen Form getrennt bereitgestellt. Als Entwicklungsumgebung
und Testplattform kommt das Java 2 SDK sowie die BeanBox aus dem BDK 1.1
der Firma Sun Microsystems, Inc. zum Einsatz. Im Vergleich zu anderen Java-Entwicklungsumgebungen sind
diese zwar recht spartanisch ausgestattet, dafür aber für eine
Vielzahl von Hardwareplattformen kostenlos verfügbar . Im Folgenden werden zunächst kurz JavaBeans im allgemeinen, der
abstrakte Aufbau des Cache-Simulators im Überblick und schließlich
die einzelnen Simulator-Beans im Detail dargestellt.
. Um eine entsprechende Komponententechnologie auch für Java zu ermöglichen,
erstellte Sun die JavaBeans-Spezifikation. Darin werden allgemeine Anforderungen
an Beans, wie die entsprechenden Softwarekomponenten treffenderweise genannt werden,
festgelegt, die wie Entwurfsmuster verstanden werden sollen und bei ihrer Einhaltung eine Zusammenarbeit
mit visuellen Entwicklungssystemen unterschiedlicher Hersteller und Plattformen
ermöglichen. Beans, die dieser Spezifikation entsprechen, müssen
mindestens die folgenden Kriterien erfüllen:
bezogen werden. Die in dieser Arbeit entwickelten Softwarekomponenten
entsprechen ebenso wie alle AWT- und SWING-Komponenten der JavaBeans-Spezifikation. Zur vereinfachten Anwendung als
Klassenbibliothek werden jedoch noch weitere, über den Rahmen der
Spezifikation hinausgehende, öffentliche Methoden und Konstruktoren
implementiert.
 |
eingeführt, dass ein effizientes Eventhandling ermöglicht. Seine
Basis beruht auf drei Konzepten, für die jeweils eine entsprechende
abstrakte Klasse existiert:
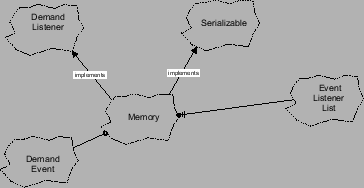
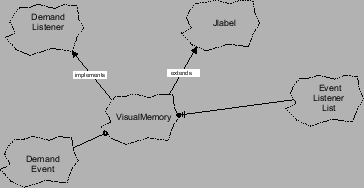
, das geschrieben oder gelesen werden soll.
 |
 |
. In diesem Format sind alle Speicherreferenzen mit einem Label versehen,
der angibt, um welche Art von Zugriff es sich handelt. ReadTrace liest das File zeilenweise, decodiert die Zugriffsart
und generiert daraus jeweils ein entsprechendes DemandEvent Objekt. Bean
Properties
 |
![\begin{deflist}{traceName:}\item [traceName:] Über diese Property wird der Dat......tepped = true) und kontinuierlicher Simulation (stepped = false),\end{deflist}](img47.png)
 |
![\begin{deflist}{replacementPolicy:}\item [cacheName:] Name der Cachekomponente......lten bei Schreibzugriffen\item [copyBack:] Rückschreibstrategie\end{deflist}](img49.png)
 |
![\begin{deflist}{replacementPolicy:}\item [cacheName:] Name der Cachekomponente......riffsdarstellung pro Speicherzelle (0-kein automatisches Löschen)\end{deflist}](img51.png)
 |
 |
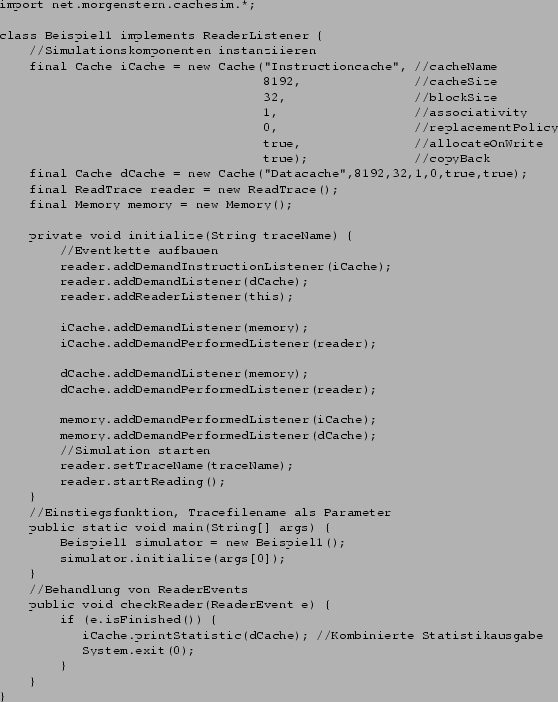 |
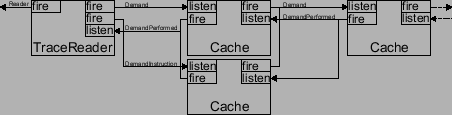
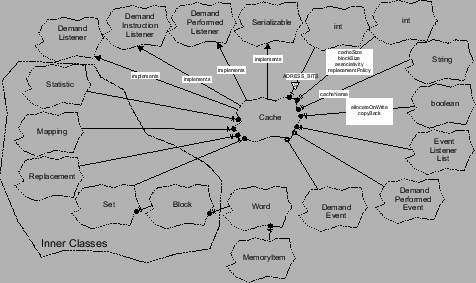
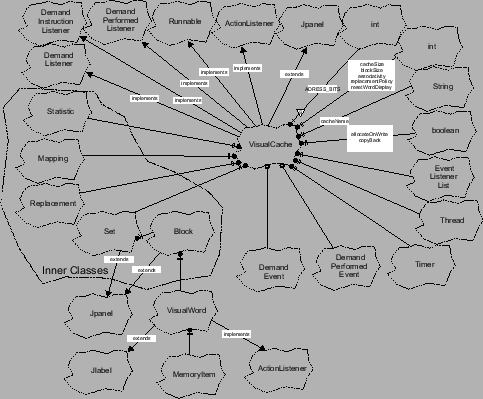
und verbindet sie in ihrer Methode initialize() über das definierte Eventsystem. Allein durch die Registrierung des
Objekts iCache an der DemandInstructionListener Schnittstelle wird der Aufbau eines Splitcache erreicht. Diese Registrierung
der Eventlistener entspricht dem "Pfeile zeichnen" in grafischen
Entwicklungstools und stellt die eigentliche Funktionalität des Simulators
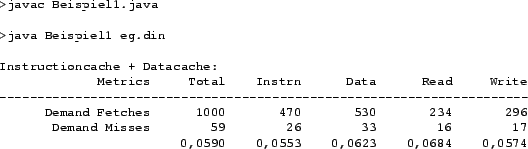
bereit. Ein Testlauf der Applikation mit dem Testtrace der dineroIII Installation ergibt die Ergebnisse in Abbildung fig:res_1.
 |
![\begin{figure}\begin{center}\leavevmode{\footnotesize\begin{verbatim}........mulator.initialize(args[0]);}}\end{verbatim}}\end{center}\end{figure}](img56.png) |
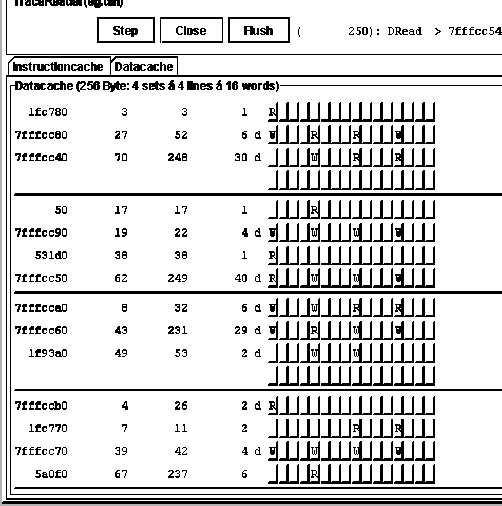 |
vorliegen müssen. Diese wird in ein bestimmtes Verzeichnis kopiert und dann automatisch, oder über einen speziellen Menüpunkt
in das Entwicklungssystem integriert.
 |
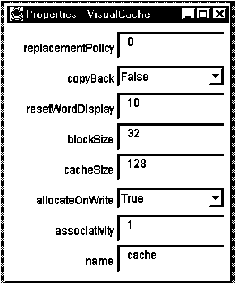
. Ist dies erfolgreich abgeschlossen, stehen die Beans dann als Komponenten
in einer Form von Toolbox zur Verfügung (Abbildung fig:bb_tb).
 |
 |
 |
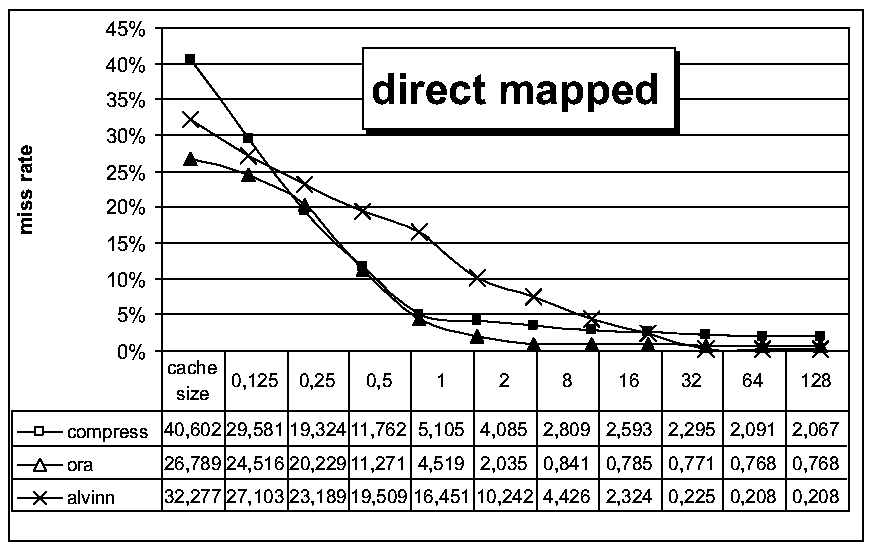
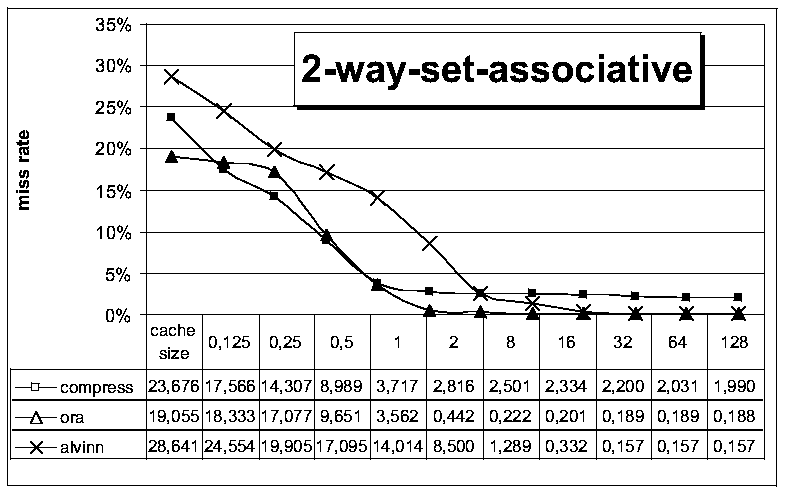
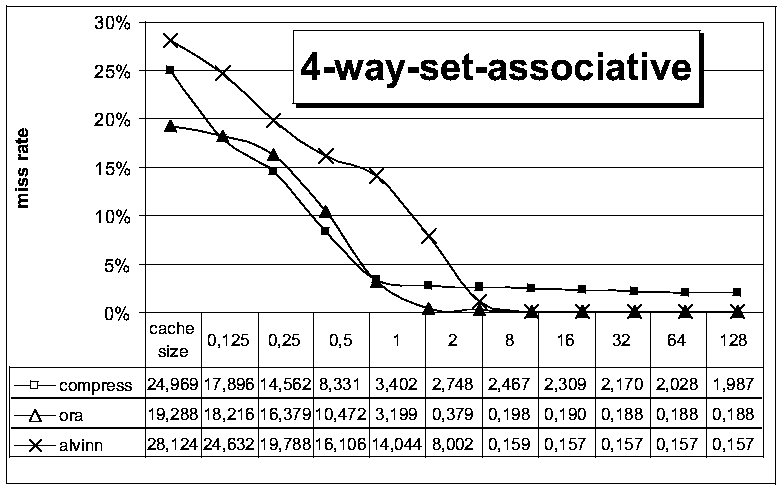
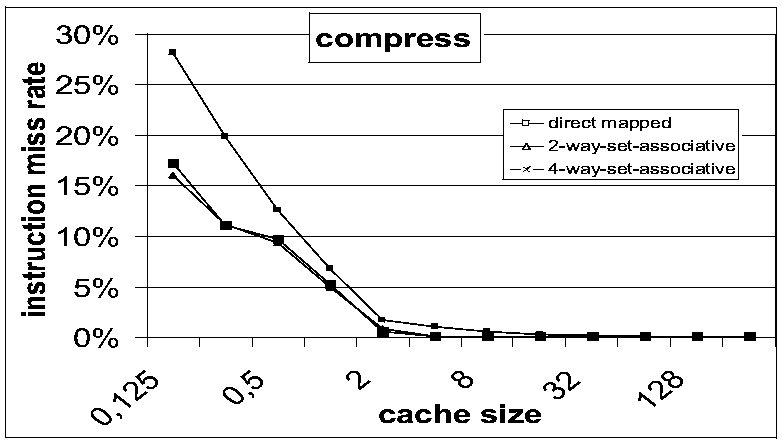
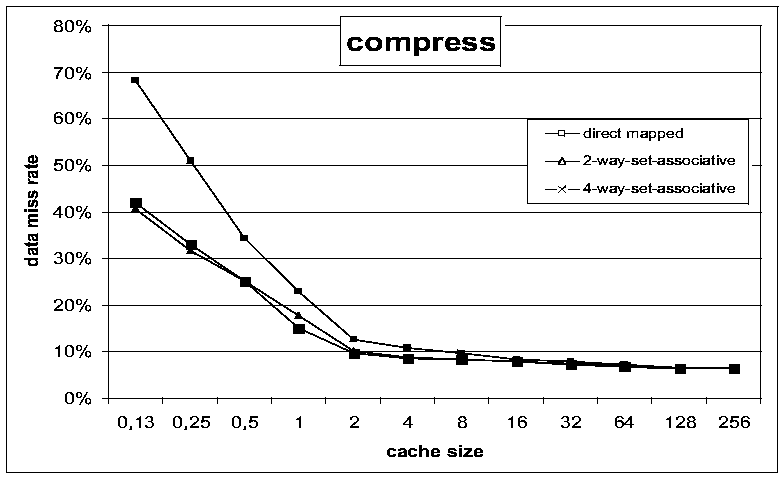
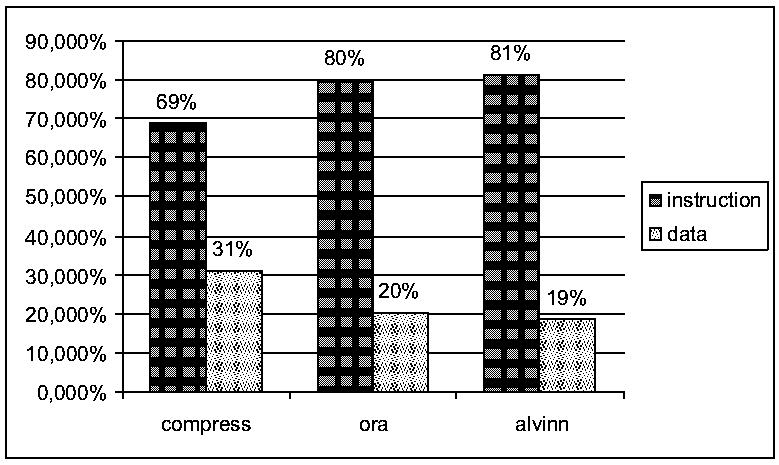
. In vergleichbaren Designs ergaben sich dabei auch übereinstimmende
Simulationsergebnisse. Im Rest dieses Kapitels werden beispielhaft noch
einige statistische Simulationsergebnisse präsentiert. Dazu wurde
mit den beschriebenen Methoden ein einstufiger, nichtvisueller Cachesimulator
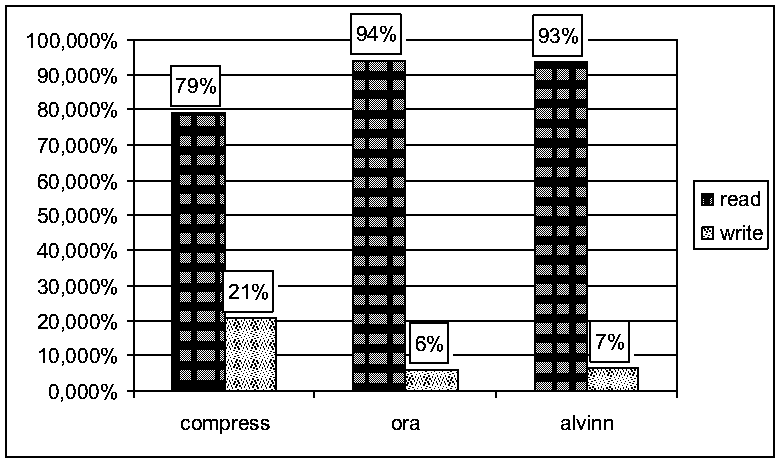
aufgebaut und Traces der Programme compress, ora und alvinn simuliert. Als Designparameter kamen eine Blockgröße von 32
Worten, ein LRU replacement und eine write allocate Strategie zum Einsatz.
Die Cachegröße wurde zwischen 128 und 256k Worten variiert und
jeweils mit einem direct mapping, einem 2-way und einem 4-way set associative
mapping kombiniert.
 |
 |
 |
 |
 |
 |
 |
Tex2HTML generiert von Gerald Heim (DANKE Gerald!!!)